I have watched and re-watched Seinfeld over and over for the last 6–7 years now and it remains, till date, one of my most favorite shows. For a show that claims to be about nothing, it has certainly managed to fill up nine seasons worth of content, all with seemingly no plot.
The show, if you’re unfamiliar with it, traces the day-to-day lives of (mainly) 4 quite unremarkable people — Jerry Seinfeld, George Costanza, Cosmo Kramer and Elaine Benes. These 4, along with plenty of other side characters and guest stars engage in what seems to be a series of meaningless conversations and activities, which somehow all come together towards the end of the duration of each episode.
Yesterday while animatedly watching one of the episodes in which Frank Costanza talks about the a festival he had created, “Festivus”, I found myself thinking how much I adored Frank Costanza as a character. But he hadn’t featured in many episodes right? Neither had Jackie Chiles, the versatile lawyer, and yet he’d had the same effect as had Frank. Which episodes were those again? Damn. You’d thinking having watched this show so many times, such information would be “tattooed in my brain”. But admittedly, it was not. And there Had to be a more complicated, yet fun way to get this information than looking it up on Wikipedia. And thus, the weekend data-dive game was on.
The measure used in this analysis is the number of times a person has a line to speak per episode. So it follows that the first time a person (say Jackie Chiles) had a line throughout the show would be the first time he/she was featured. Other results that followed were how important a character was to the show or an episode, or in how many episodes was say, Elaine or Kramer, not present. Also, we know the central 4 characters, but how do the 3 characters apart from Jerry rank against each other? So, this is how I went about it.
Scraping and parsing the data.
I obtained the list of episodes and scraped every episode’s script off of seinfeldscripts.com
The data scraped was neither very manageable nor consistent in the form obtained. So a pattern was slightly troublesome to derive, but finally I found a way to just get the dialogues and more importantly, the person who delivered them using Beautiful Soup (bs4).
soup = BeautifulSoup(req.content, ‘html.parser’)
paragraphs = soup.find_all('p')
.
.
.
if (j.isupper() and len(j)>1 and ‘:’ in j):
if j in chars_dict:
chars_dict[j]=chars_dict[j]+1
chars_dict[‘TOTAL’]=chars_dict[‘TOTAL’]+1
else:
chars_dict[j]=1
chars_dict[‘TOTAL’]=chars_dict[‘TOTAL’]+1
In case it was a well written script, the pattern would be something like - KRAMER: “Hoochiemama!”
And the above mentioned code snippet would handle. But in many of the files you had entries like - George: “Vandelay Industries! Say Vandelay Industries”
And the only indication here that a dialogue has begun is the colon (“:”). So this was the other case to handle.
Storing and filtering the data
Looping through the entire set of scripts resulted in a dictionary of dictionaries, where the key was an episode number and the value was a dictionary of the cast for that episode with their corresponding counts of dialogues.
Next I consider the characters I’m primarily interested in, since for this usecase, I don’t really care about some people like Sue Ellen Mischke or Stan the Caddy.
characters =[“JERRY”,”GEORGE”,”ELAINE”,”SUSAN”,”KRAMER”,”JACKIE”,”FRANK”,”RAVA”,”NEWMAN”,”TOTAL”]
After translating the keys of the dictionary obtained in Step 3 to uniformly be in upper case, I store the occurrence values per episode for the characters mentioned above along with the total number of dialogues per episode (“TOTAL”) in a dataframe since Pandas is a very good tool to manipulate data.
The occurrence values were then normalized to be in percentages of the TOTAL.
Despite all the attempts to obtain complete data, there were some files i.e. episode scripts that were able to be only partially processed or were unable to be processed because there was no way to distinguish beyond a shadow of the doubt between the character names and the dialogues themselves. This was obviously because the only source considered was Seinfeldscripts.com. A future experiment will probably consider other sources to fill in the missing data. To this end, I’ve filtered out entries that had a TOTAL value < 100
df = df[df.TOTAL > 100].sort_values(by=”episode_num”)
The finale episodes have also been omitted from this analysis.
Results:
The main result was a set of graphs based on the following criteria I chose -
- % of dialogues per episode of Elaine vs Kramer
- % of dialogues per episode of Elaine vs George
- % of dialogues per episode of George vs Kramer
- Episodes in which Frank Costanza featured
- Episodes in which Susan featured
- Episodes in which Jackie Chiles featured
- Episodes in which Newman featured
Other miscellaneous graphs were also computed.
The X-axis for all graphs shows the episode number (albeit unclear) and the Y-axis tracks the % occupied per episode.
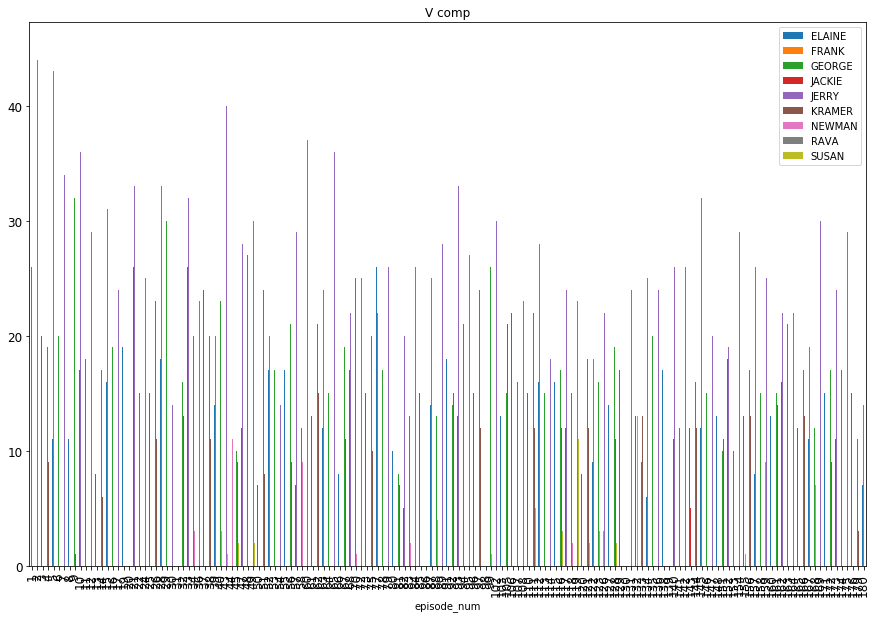
Understandably, Jerry has the largest number of dialogues in every episode.
1. Elaine vs George :
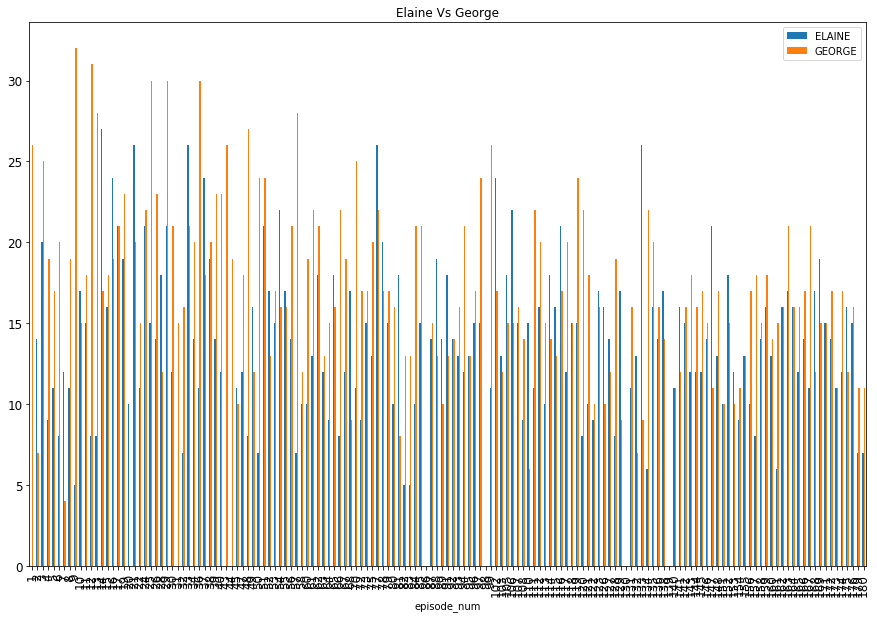
The trend shows that George (~20–30%) always has more screen space than Elaine(~5–25%) .
2. Elaine vs Kramer :
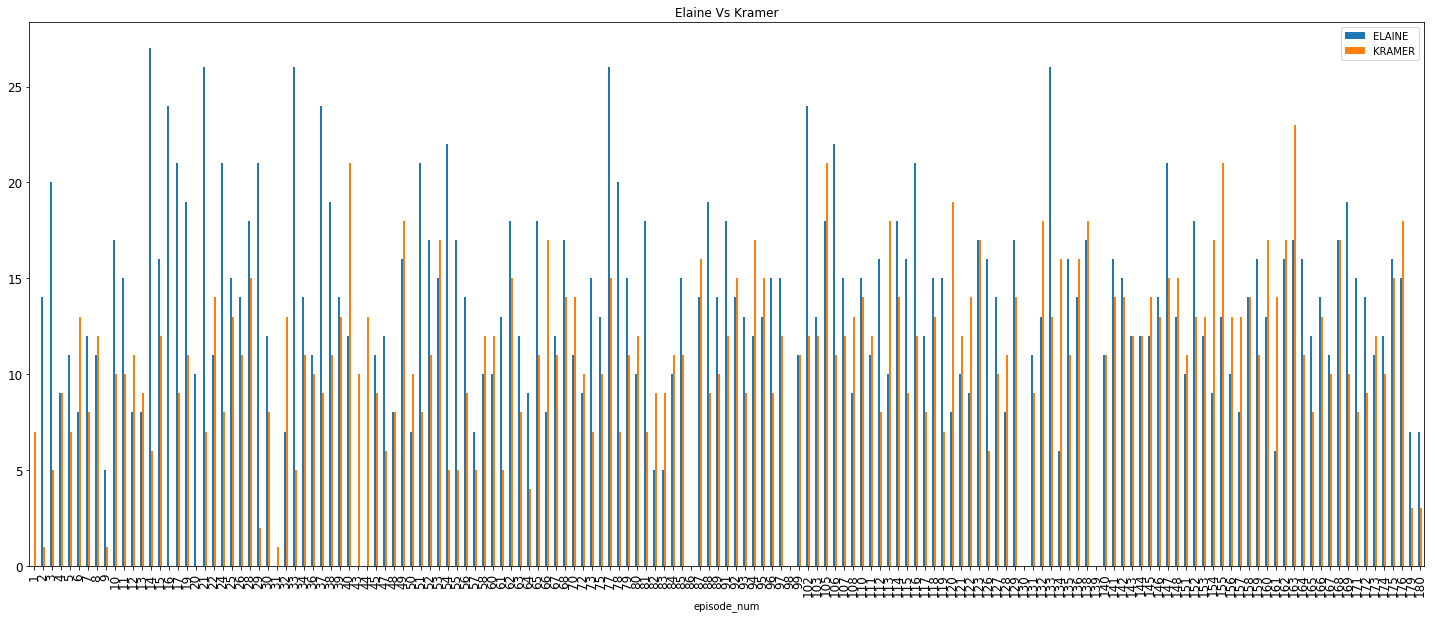
While they seem to be uniformly matched for the most part, it looks like Elaine almost always has more to say than Kramer, atleast for the first 60% of the total number of episodes. Towards the end however, Kramer seems to be having more to say.
3. George vs Kramer:
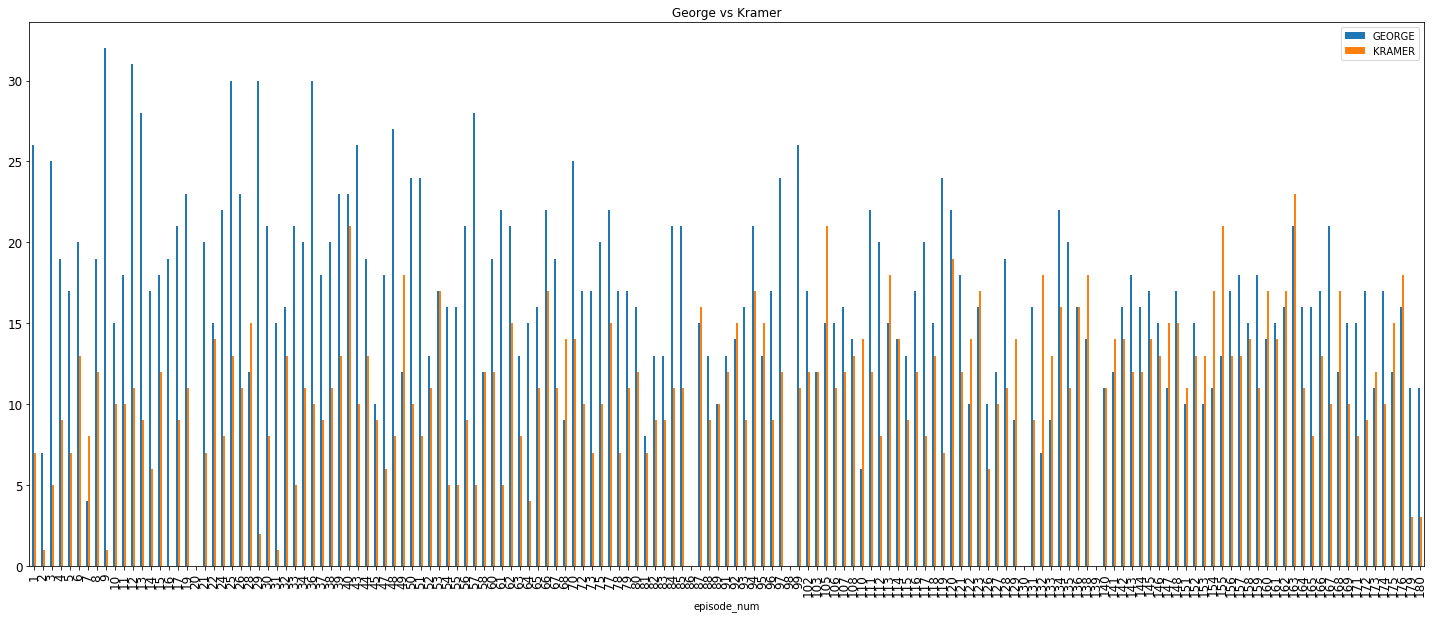
No surprises here. George dominates with ~20–30% of the conversations while Kramer averages out at close to 15% of the conversations.
So, we see that in terms of main character importance, Jerry > George > (Elaine = Kramer). Moving on,
4. Frank Costanza:
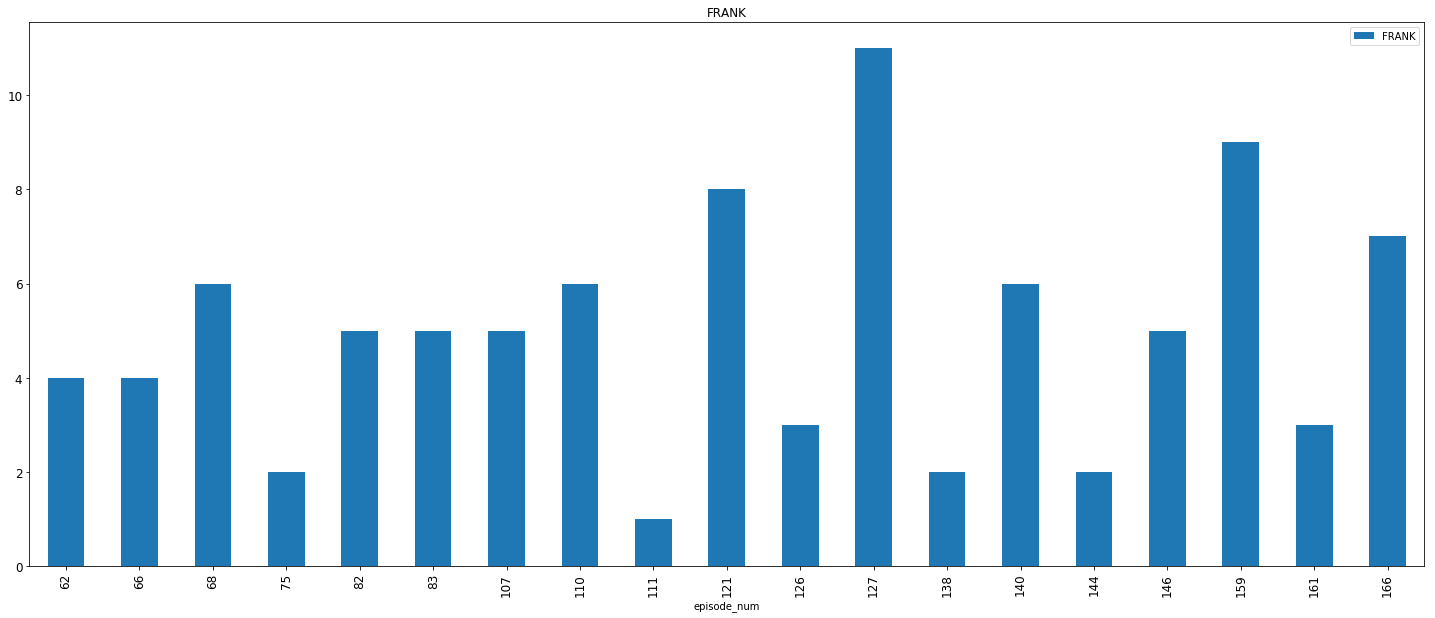
Frank Costanza first appears in episode 62 — “The Handicap Spot” and finally in episode 166 — “The Strike” (the legendary Festivus episode) barring the finale episodes.
5. Susan Ross
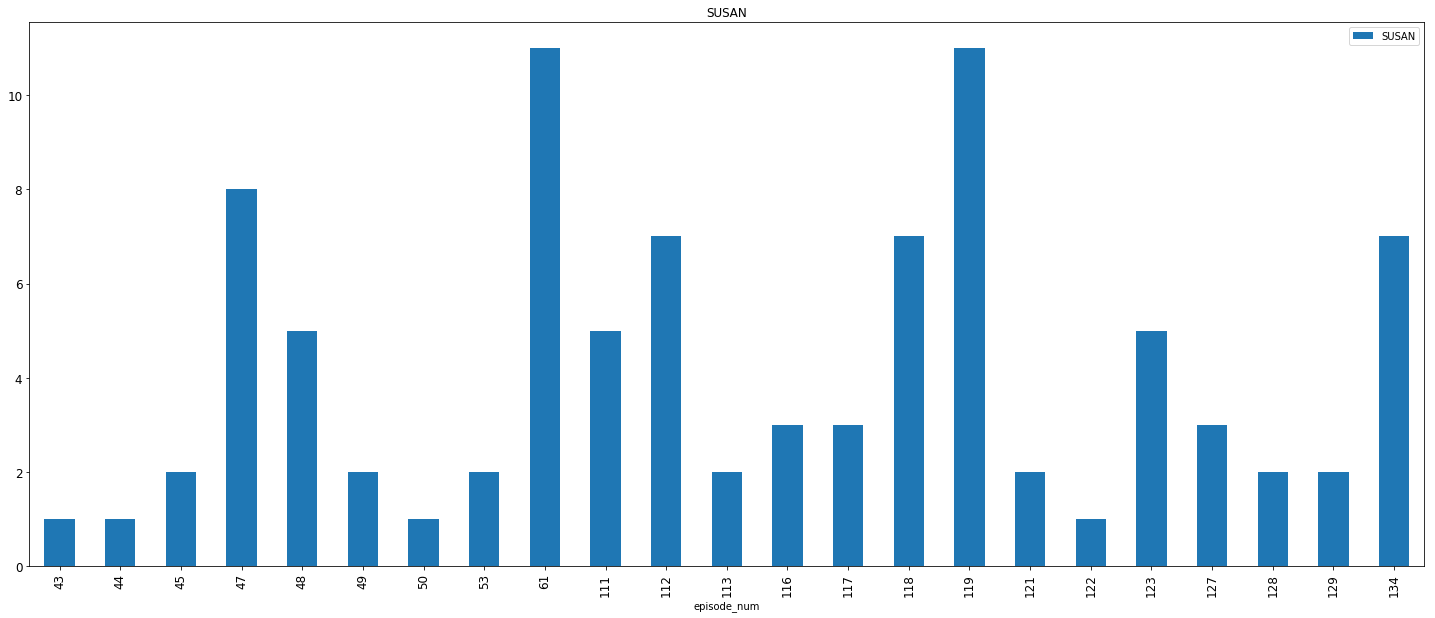
Susan first appears in episode 43 — “The Pitch” and finally in episode 134 — “The Invitations”, when… you know..
6. Jackie Chiles
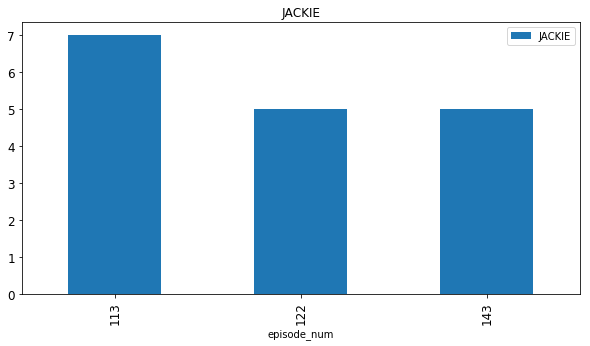
Jackie Chiles plays a major role in only 3 episodes Episodes 113, 122 and 143, again barring the Finale. I finally have my answer :D
7. Newman
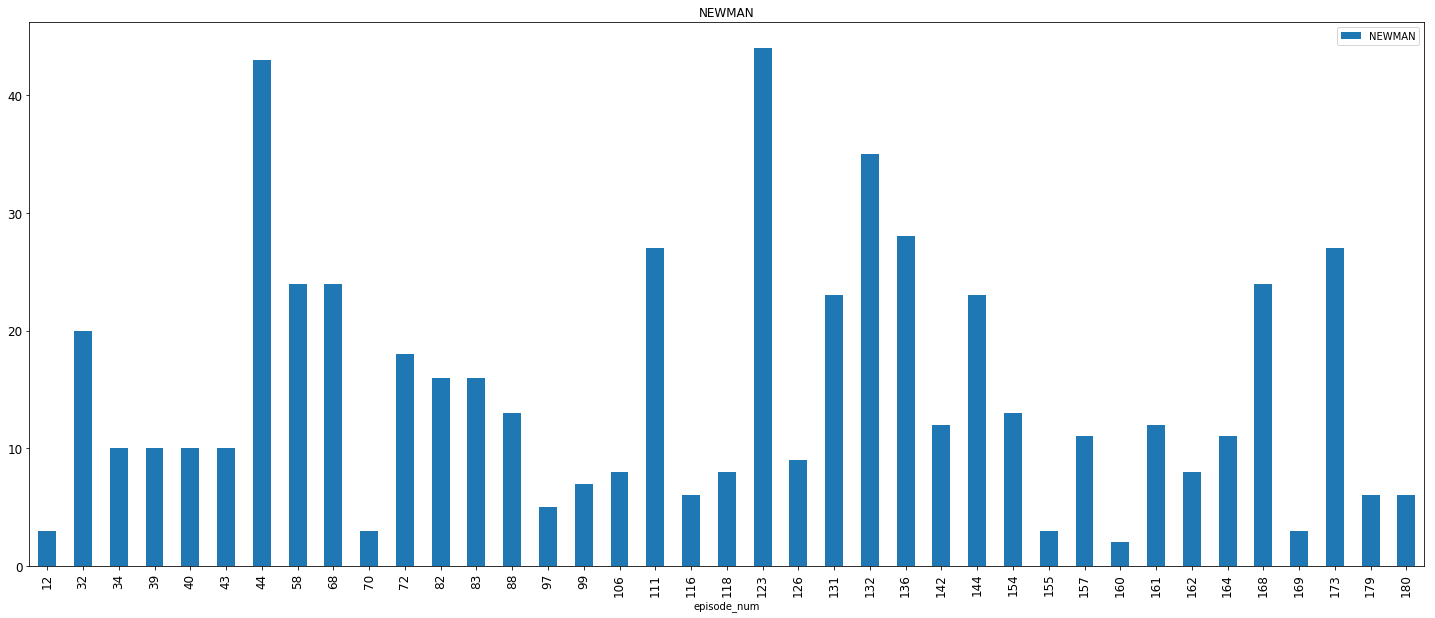
We see that Newman plays a key role in more episodes than any of the other side characters, going upto 14% in episode 132 — The Bottle Deposits — part 2 where he runs a bottle scam with Kramer (Aah nostalgia).
This experiment was a lot of fun. I hope to fill in the blanks in the next ones and also work out stats and relationships for the other characters.
SERENITY NOW!!!!
[1] http://www.seinfeldscripts.com/seinfeld-scripts.html
[2] Code : https://github.com/abhiramr/DataViz/blob/master/Seinfeld/Seinfeld_Analysis.ipynb